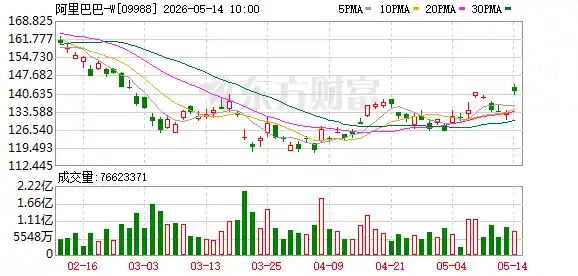
科金社2025年08月05日 07:32消息,阿里通义千问发布Qwen-Image,开启中文高保真图像生成开源新时代,助力AI创作更智能、更高效。
8月5日,阿里通义千问团队正式宣布开源其首个图像生成基础模型——Qwen-Image。这一重磅发布标志着通义千问系列在多模态领域迈出了关键一步。Qwen-Image基于20B参数规模的MMDiT架构,专注于解决当前生成模型在复杂文本渲染与精确图像编辑中的核心难题,一经发布便引发业界广泛关注。
该模型最引人注目的突破在于其卓越的文本渲染能力。Qwen-Image能够精准处理多行布局、段落级文本生成,并在中英文字符的细节呈现上实现高保真输出。这在当前主流图像生成模型普遍难以准确生成可读文字的背景下,堪称一次技术跃迁。尤其在中文场景下,模型对书法体、排版逻辑乃至文化语境的理解,展现出远超现有SOTA模型的表现力。
从实际示例来看,Qwen-Image不仅能生成如“义本生知人机同道善思新,通云赋智乾坤启数高志远”这样结构严谨、字体飘逸的对联,还能将“千问”字样巧妙融入酒缸与代码溶液的创意设定中,体现出对中文语义与视觉美学的深度融合。这种能力不仅提升了图像的信息承载量,更为品牌宣传、文化创意等实际应用场景打开了全新可能。
在图像编辑方面,Qwen-Image通过增强的多任务训练范式,实现了高度一致性的编辑能力。无论是风格迁移、对象增删,还是人物姿态调整与细节增强,模型都能在保持整体结构合理的同时完成精细操作。这意味着普通用户无需专业设计软件或技能,即可完成过去需由设计师耗时完成的复杂编辑任务,极大降低了创意表达的门槛。
尤为值得关注的是,通义千问团队在多个权威基准上对Qwen-Image进行了全面评估。在GenEval、DPG、OneIG-Bench等通用生成测试中,以及GEdit、ImgEdit、GSO等编辑专项测试中,Qwen-Image均取得领先性能。而在专为长文本设计的LongText-Bench、ChineseWord和TextCraft测试中,其表现更是大幅超越现有模型,特别是在中文文本生成质量上树立了新的标杆。
这一成果的背后,反映出阿里在大模型多模态布局上的深远考量。相较于单纯追求“以图生图”的娱乐化路径,Qwen-Image更强调实用性与语义理解能力,尤其是在中文语境下的本土化优化,体现了国产模型从“能用”向“好用”的实质性转变。这种以解决真实问题为导向的技术路线,或将重塑国内AIGC生态的发展方向。
目前,Qwen-Image已在ModelScope、Hugging Face及GitHub平台全面开源,配套技术报告与在线Demo也已同步上线。开放的姿态不仅有助于推动学术研究,更为开发者社区提供了强大的工具支持。可以预见,随着更多开发者接入与二次创新,Qwen-Image有望成为中文图像生成领域的重要基础设施。
当前AI图像生成正从“视觉冲击”走向“语义精准”,Qwen-Image的发布恰逢其时。它不仅是技术层面的一次突破,更是对“AI能否理解中文文化”的有力回应。未来,谁能在语义、审美与功能之间找到最佳平衡点,谁就有可能真正掌握下一代内容创作的主动权。













留言评论
(已有 0 条评论)暂无评论,成为第一个评论者吧!